|
I am currently a Postdoctoral Researcher at Spatial Intelligence and Robotics Lab, Westlake University, led by Prof. Peidong Liu (刘沛东). Before that, I worked at City Brain Lab, Alibaba DAMO Academy as a Senior Algorithm Engineer. I obtained my B.S. degree from Harbin Institute of Technology in 2017, and obtained my Ph.D. degree from Zhejiang University in 2022. My doctoral advisor is Prof. Haibin Shen (沈海斌). My research focuses on Spatial Intelligence, especially 3D-Grounded Representation, World Model, and World Action Model. I have published papers in top-tier venues such as CVPR, NeurIPS, AAAI, ACM MM, TMM, and TCSVT. 🔥 I am looking for research or industry positions in the field of Spatial Intelligence, especially in areas related to World Models, World Action Models and 3D AIGC. Feel free to reach out! Email | Google Scholar | GitHub | RedNote |

|
|
Equal Contribution *, Corresponding Author ✉️, Project Lead † |
|
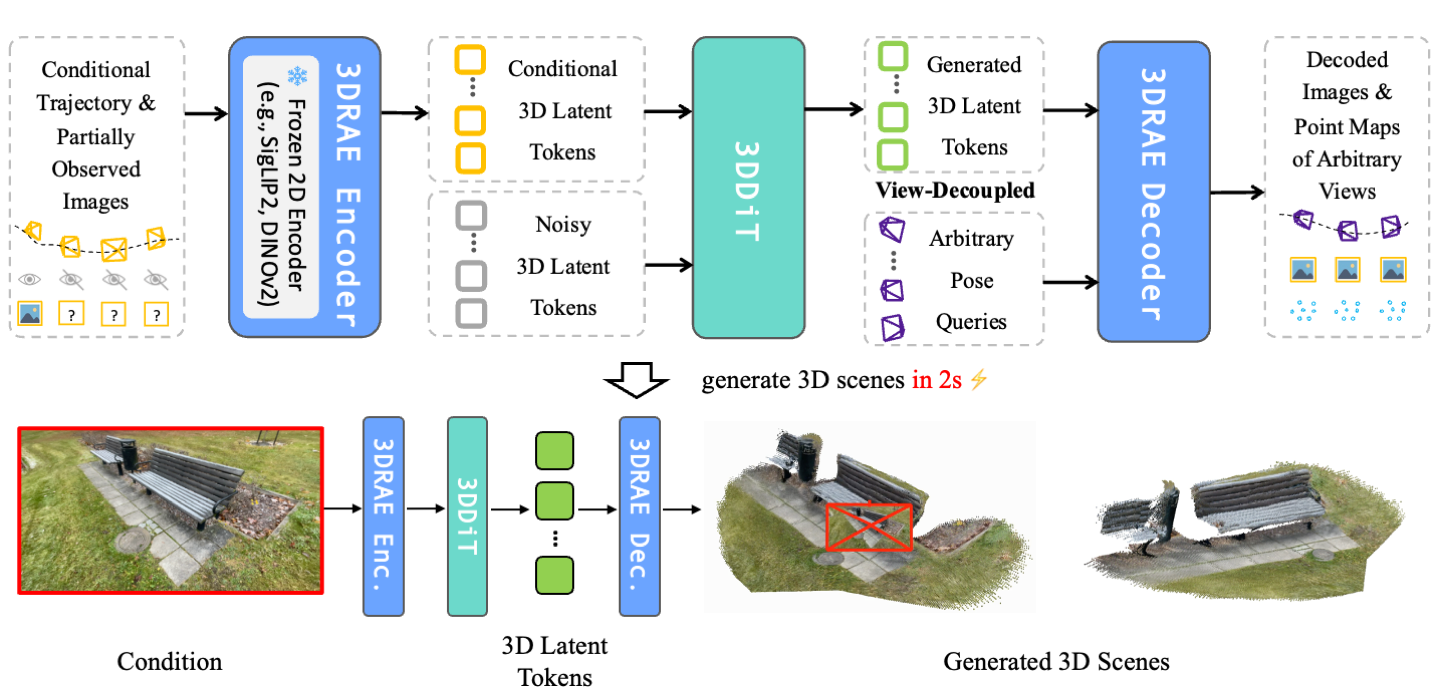
Dongxu Wei *, Qi Xu *, Zhiqi Li, Hangning Zhou †, Cong Qiu, Hailong Qin, Mu Yang, Zhaopeng Cui, Peidong Liu ✉️ arXiv 2026 project page / arXiv / code Represent 3D scenes with fixed-length 3D latent tokens and perform diffusion modeling directly within 3D latent space. |
|
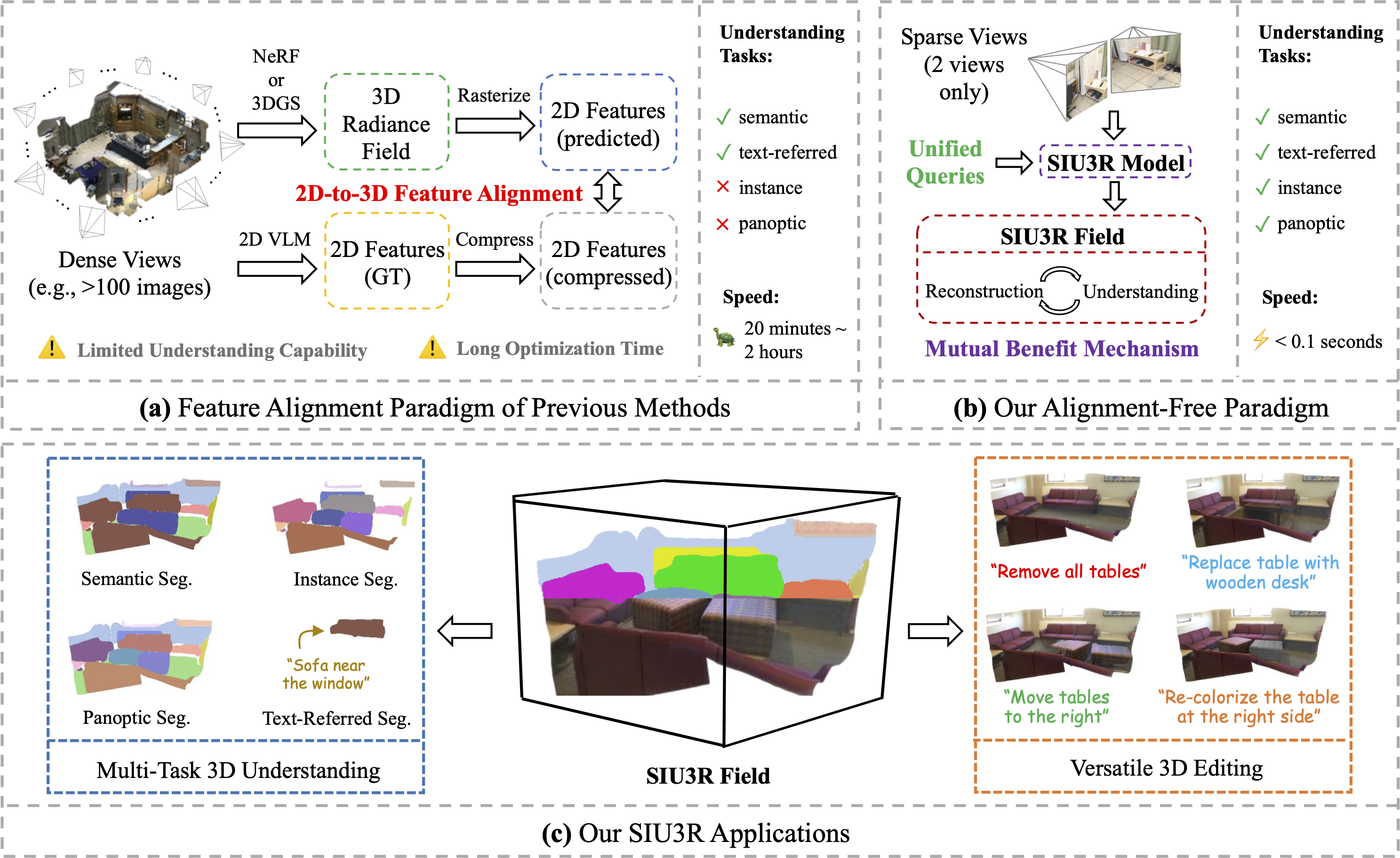
Qi Xu *, Dongxu Wei * ✉️, Lingzhe Zhao, Wenpu Li, Zhangchi Huang, Shunping Ji, Peidong Liu ✉️ Annual Conference on Neural Information Processing Systems (NeurIPS), 2025. Spotlight paper, top 3% project page / arXiv / code The first alignment-free method for unified 3D reconstruction and understanding. |
|
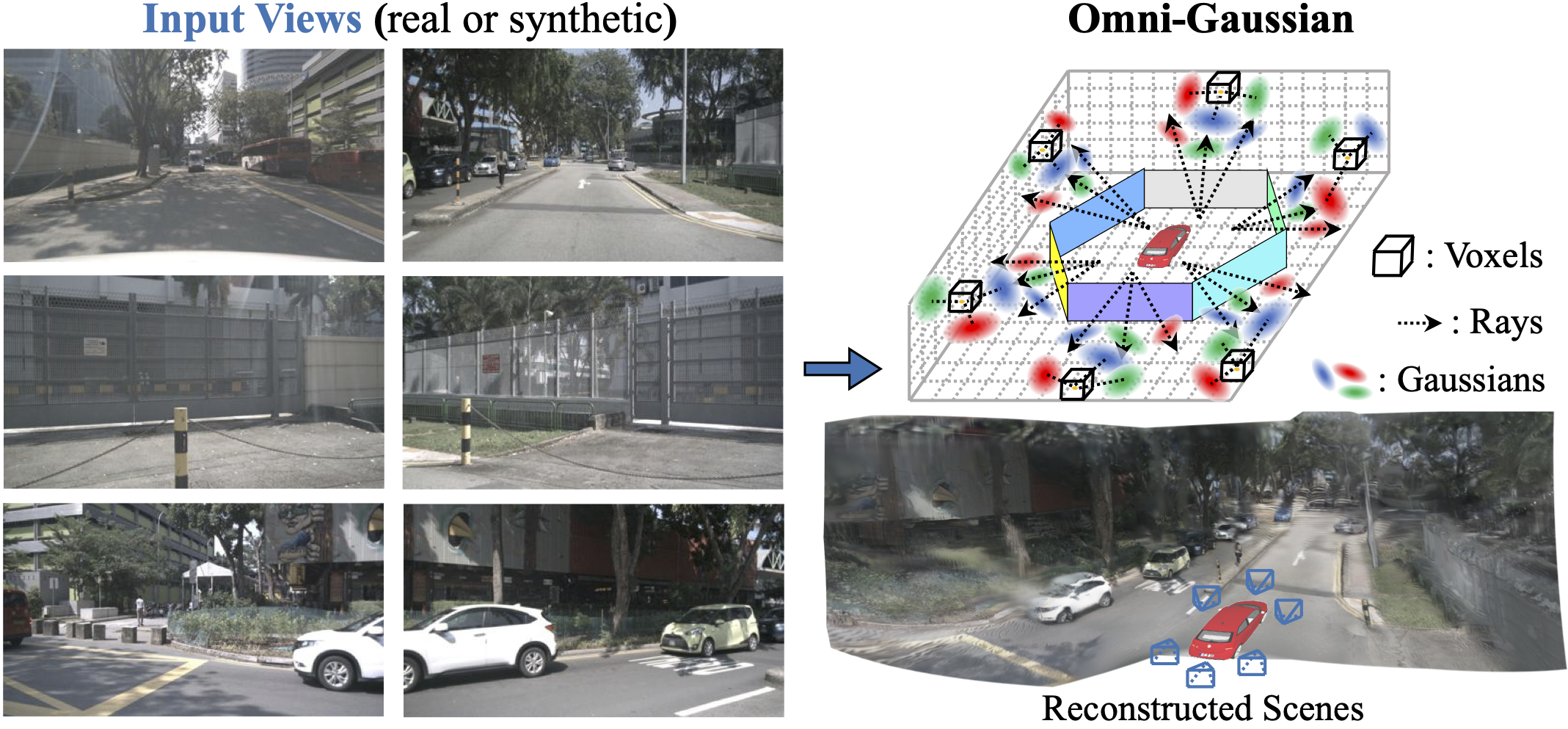
Dongxu Wei, Zhiqi Li, Peidong Liu ✉️ IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 project page / arXiv / code Unify pixel-based and volume-based Gaussians within a single framework, and make them complement each other for ego-centric and large-scale 3D scene reconstruction. |
|
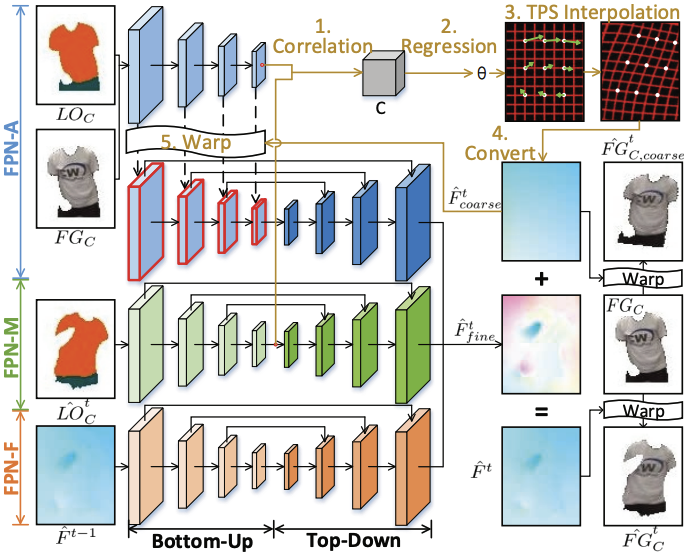
Dongxu Wei, Xiaowei Xu, Haibin Shen, Kejie Huang ✉️ AAAI Conference on Artificial Intelligence (AAAI), 2021. Oral presentation. arXiv / code Warp images with estimated flows rather than generate videos from scratch for spatial-temporal consistent motion transfer. |
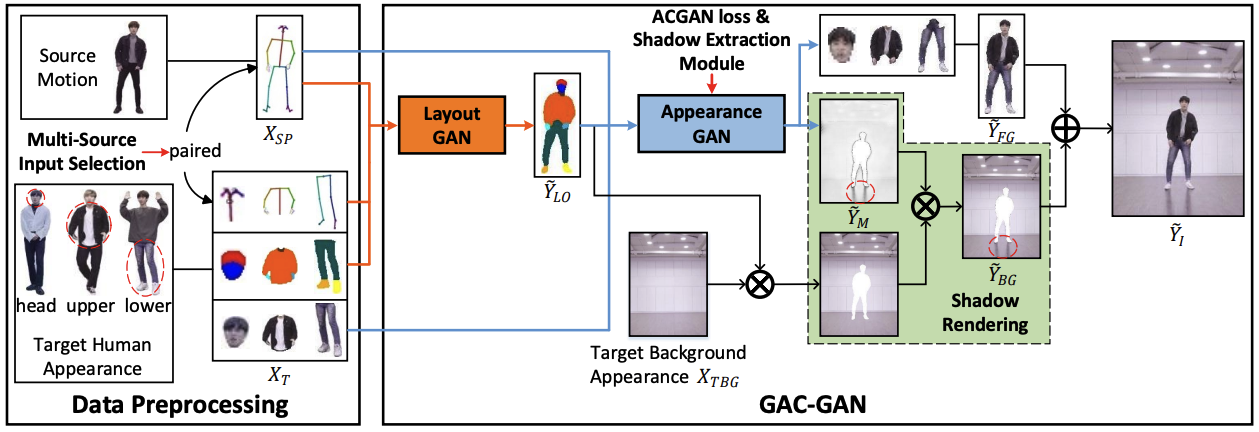
|
Dongxu Wei, Xiaowei Xu, Haibin Shen, Kejie Huang ✉️ IEEE Transactions on Multimedia (TMM), 2020. arXiv / code A two-stage human video generation method with general-purpose and part-level controllability. |
|
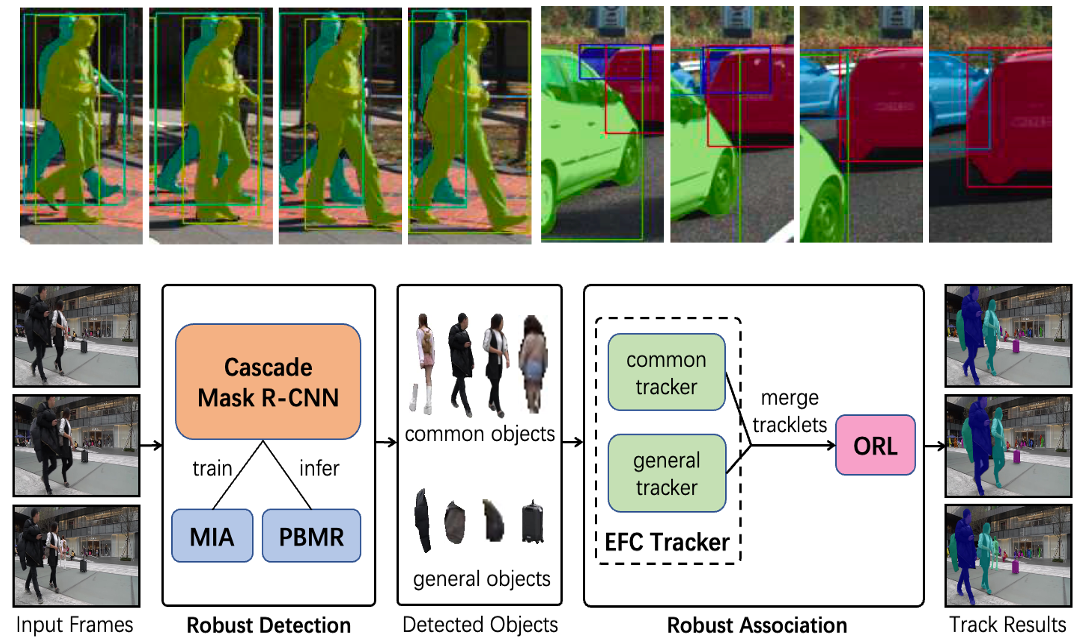
Dongxu Wei, Jiashen Hua, Hualiang Wang, Baisheng Lai, Kejie Huang, Chang Zhou, Jianqiang Huang, Xiansheng Hua IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021 | paper 🏆 The 1st-place solution for the CVPR 2021 Robust Multi-Object Tracking and Segmentation (RobMOTS) Challenge. |


|
Dongxu Wei, Kejie Huang ✉️, Liyuan Ma, Jiashen Hua, Baisheng Lai, Haibin Shen Applied Intelligence, 2023 | paper A unified framework that can achieve human motion transfer, attribute editing and texture inpainting. |
|
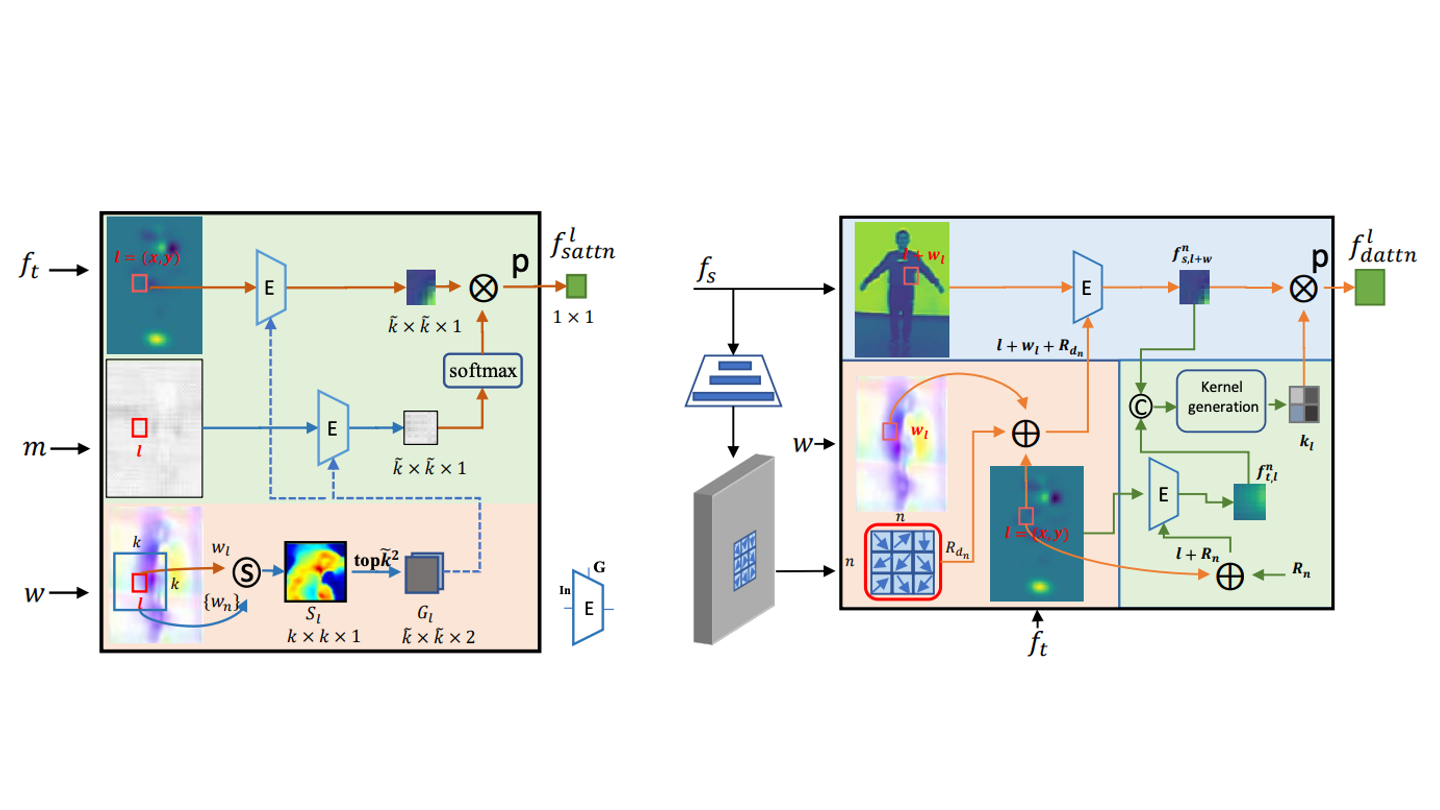
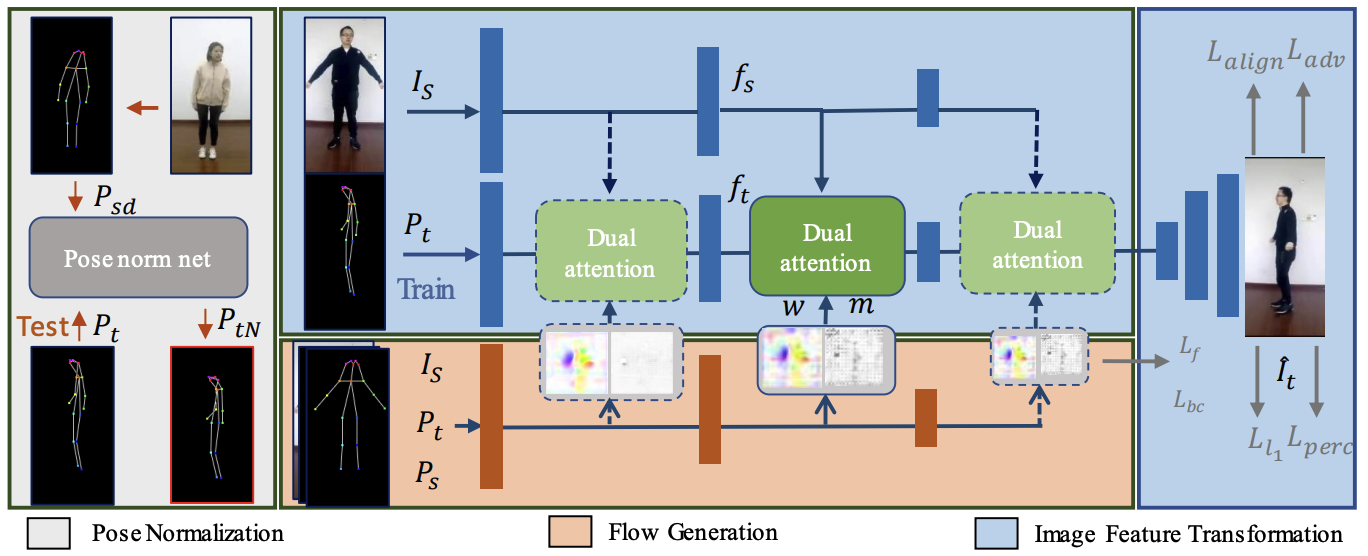
Liyuan Ma, Kejie Huang ✉️, Dongxu Wei, Zhaoyan Ming, Haibin Shen IEEE Transactions on Multimedia (TMM), 2021 | paper Flow-based dual attention that enables deformable- and occlusion-aware fusion for enhancing fidelity of human image synthesis. |
|
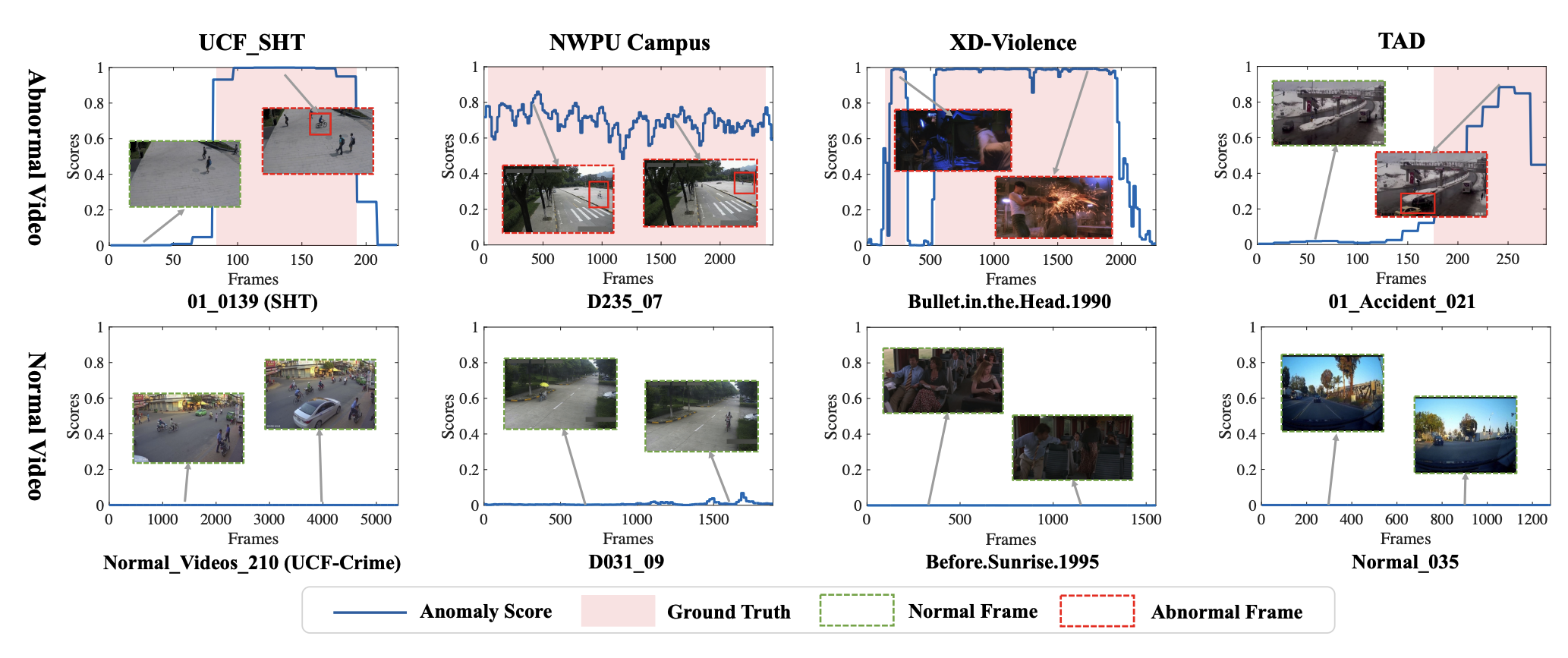
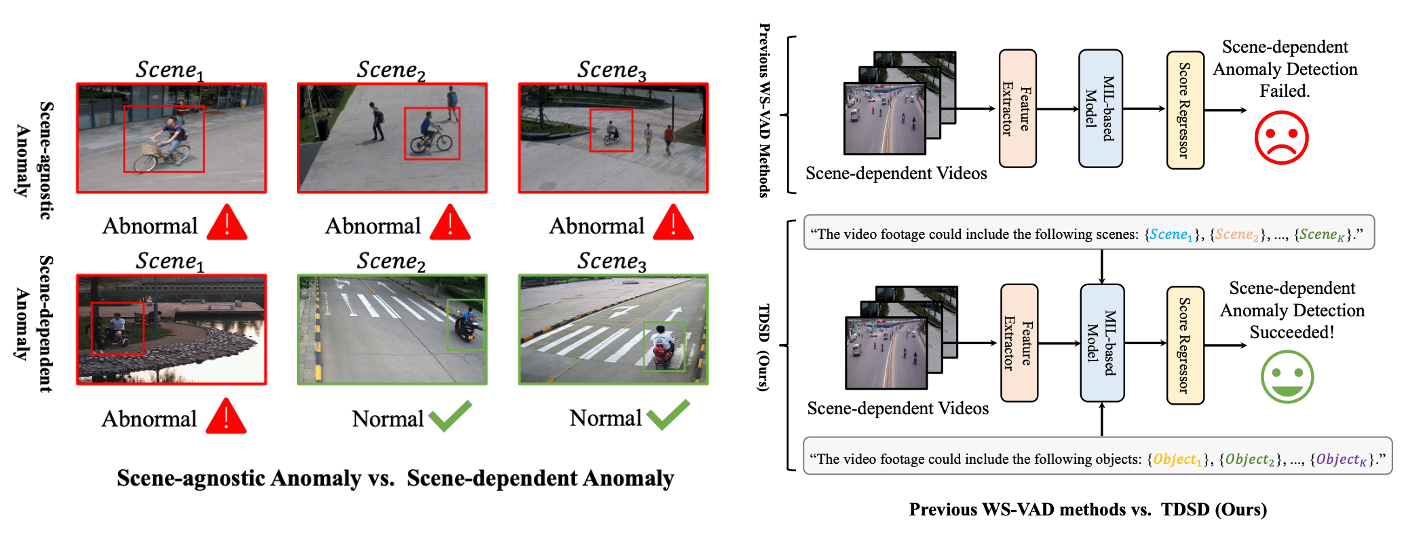
Shengyang Sun, Jiashen Hua, Junyi Feng, Dongxu Wei, Baisheng Lai, Xiaojin Gong ✉️ ACM International Conference on Multimedia (ACMMM), 2024 paper / code The first work to address scene-dependent video anomaly detection under a weakly supervised setting. |

|
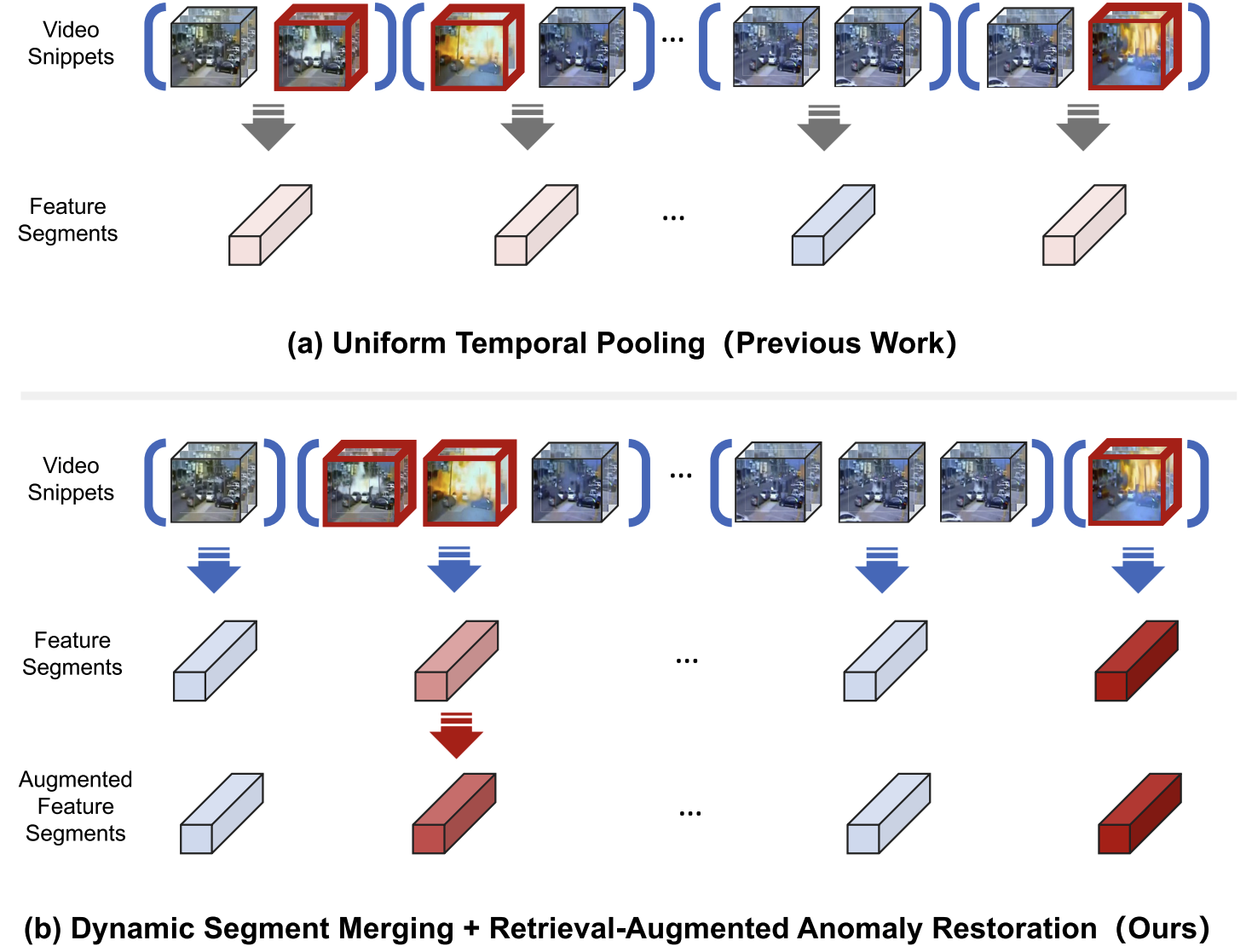
Shengyang Sun, Jiashen Hua, Junyi Feng, Dongxu Wei, Baisheng Lai, Xiaojin Gong ✉️ IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025 | paper Formulate weakly-supervised video anomaly detection as a multi-instance modeling problem, and propose dynamic segment merging module and retrieval-augmented anomaly restoration module to tackle the problem from segment-level and feature-level, respectively. |
|
I am currently leading an open project of the state key laboratory of CAD & CG at Zhejiang University, dedicated to solving various problems related to large-scale 3D scene generation. |
|
template adapted from this awesome website
|